이 서비스를 보면 누구나 “배 보다 배꼽이 크다”라는 말을 떠올릴 것이다. 이 글에서는 내가 서비스 및 개발하고 있는 bdg.blog의 도입기와 구성을 다룬다.
왜?
이 프로젝트의 목적은 “공부”다. 필자는 “왜 그런 기술을 선택했나요?”라는 질문을 받지 않고 이것저것 시도하면서 공부하기 위해 이 프로젝트를 시작했다.
History
사실 bdg.blog는 내가 웹을 처음 공부 하면서 시작했던 프로젝트다. 당시에는 AWS ec2 인스턴스에 django와 리액트를 개발자 모드로 실행해서 배포 했었다. 당시에는 환경 관리나 CI/CD 같은 개념에 대해서도 아는 것이 없었고, 단순히 ‘웹’이 무엇이고, 어떻게 동작하는 지 공부하는 것이 주요한 목적이였다.
이후에 도커를 공부할 기회가 생겼다. 백, 프론트, DB, 웹서버(nginx)를 각각 컨테이너로 분리하고 docker-compose 로 서비스를 배포 하면서 “문서”를 통한 서비스 환경 관리가 시작됐다. docker-compose up --build -d 명령어로 처음 배포에 성공했을 때의 쾌감은 지금도 생생하다.
한 동안 도커 컴포즈를 애용 했었다. (사실 지금도 일부 프로젝트에서 사용한다.) 이 때, 쿠버네티스라는 도구를 접하게 됐다. 도커가 하나의 노드 위에서 컨테이너들을 관리하지만, 쿠버네티스는 여러 개 노드 위에서 컨테이너를 생성하고 관리한다. 특히 “컨테이너를 오케스트레이션 한다”라는 말에 매료되어 쿠버네티스를 공부하기 시작했다.
쿠버네티스 클러스터를 구축하고, 블로그 서비스를 옮겨온 뒤에도 나름 도전적인 문제들을 만들고 해결하면서 많은 공부를 할 수 있었다. 지금은 다음과 같은 구성으로 나만의 “온프레미스 블로그 서비스”를 운영하고 있다.
- 2개의 노트북으로 구성
- ubuntu 22.04
- k3s v1.25.7
- Mariadb(DB), Redis(, Minio, NextJS 로 구성된 블로그
- kaniko, harbor, argo workflows, argo events, argo cd를 활용한 CI/CD 파이프라인
클러스터 사양

집에서 온프레미스로 서버를 구축할 때, 가장 중요한 것은 전기세였다. 저렴한 가격과 높은 전력효율을 가지는 노트북으로 서버를 구축했다. 32GB 메모리가 msi 노트북에 k3s server, 삼성 노트북에 k3s agent를 설치하여 2개의 노드로 구성된 쿠버네티스 클러스터이다. 하지만, 워낙 오래되기도 했고, 여러모로 굴렸더니 요즘은 상태가 좋지 않다. 금전적으로 여유가 될 때, 다른 머신으로 교체하려고 한다.
클러스터 구조
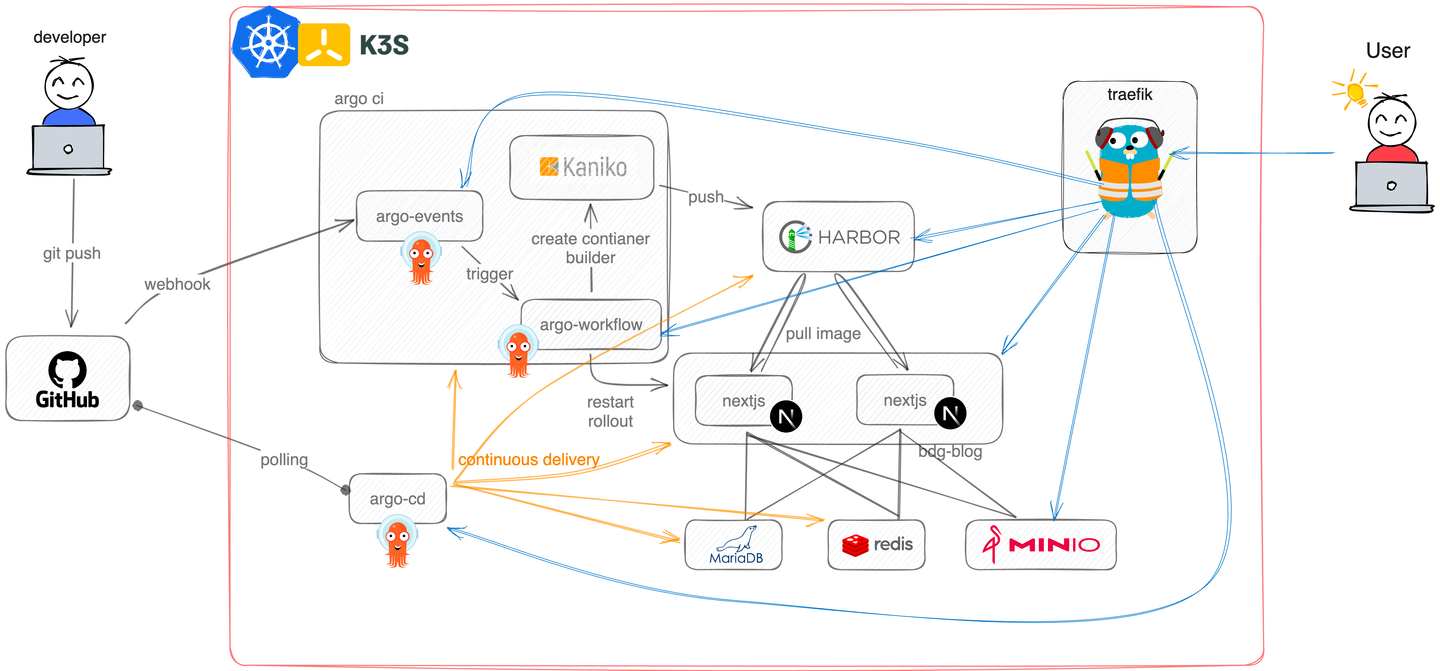
클러스터에는 다양한 서비스들이 공존하며, 네임스페이스를 통해서 구분된다. 앱의 소스코드 및 배포를 위한 명세 파일은 하나의 깃허브 레포지토리에서 관리되고 있다.
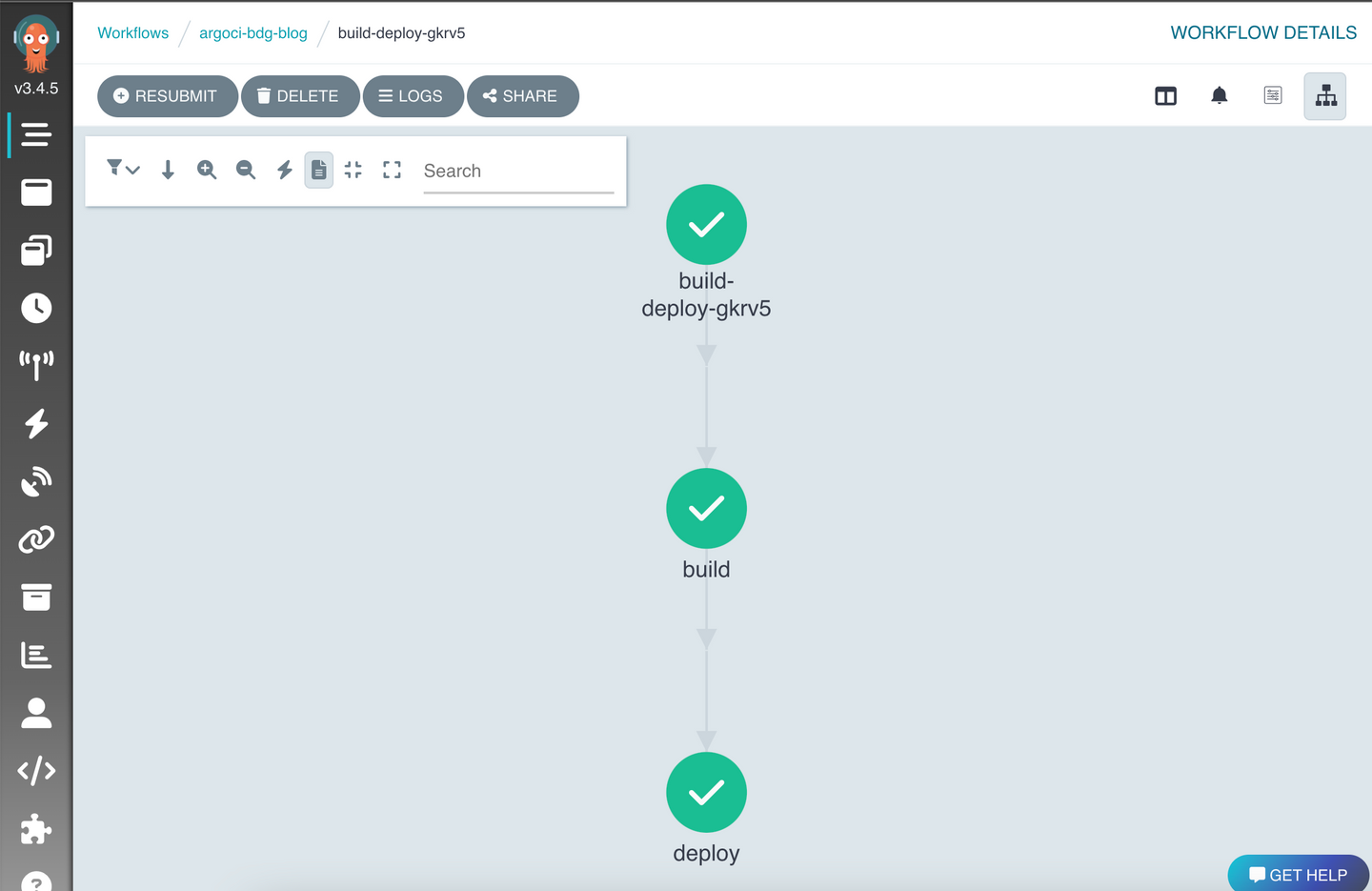
검은색 화살표는 개발자인 필자가 소스코드를 git에 push하면서 발생하는 일련의 자동 배포 과정을 보여준다. git은 argo events에 webhook을 보내고, argo events는 정해진 workflow를 실행하면서 kaniko로 컨테이너 이미지를 빌드한다. 이후 빌드가 완료되면 이미지를 harbor repository에 push한다. 마지막으로 kubectl restart rollout deployment bdg-blog -n bdg-blog 명령어를 실행하면서 기존의 컨테이너들을 교체한다.
주황색 화살표는 ArgoCD를 활용한 Continuous Delivery 과정을 보여준다. bdg.blog의 클러스터 명세는 secret 및 config 설정을 제외한 모든 코드가 kustomization.yaml 파일에 작성되어 있고, 이 파일은 git으로 관리된다. 따라서 필자가 클러스터 명세를 수정하여 git에 push하면, ArgoCD는 이 명세의 설정과 클러스터의 상태를 비교하여 변경사항을 반영한다.
마지막으로 파란색은 Ingress 컨트롤러인 traefik이 외부에서 들어오는 요청을 중계하는 과정을 보여준다. traefik은 kube-system 네임스페이스에 설치되어 있으며, Cross Namespace 범위로 동작한다. 자세한 내용은 밑에서 다룰 예정이다.
Kubernetes - K3s
사실 쿠버네티스를 공부하려면 쿠버네티스를 직접 설치하는 것 부터 해봐야 한다는 말을 들었다. 하지만 k8s를 그대로 저 노트북에 설치하기에는 여러모로 부담스러웠다. 그러던 중, 쿠버네티스와 잘 호환되면서 Edge Device에서도 잘 동작하는 K3s라는 것을 알게되었다. 기본적으로 containerd(컨테이너 런타임), flannel (CNI), traefik(Ingress Controller)등이 자동으로 설치되어 바로 사용할 수 있다. 필자는 기존 K3s 설정을 그대로 사용했다.
Main App - ns: bdg-blog
처음에는 django를 백앤드 api, 리액트를 프론트 라이브러리로 정하고 개발했다. 하지만 두 앱 사이에서 json을 시리얼라이징 하는 과정도 번거롭고, 두 앱을 따로 빌드하고 배포하는 것도 불편했다. 만약 이 프로젝트를 여러명이 개발하는 것이라면, 큰 불편함을 느끼지 못할 수도 있다. 하지만 간단한 API하나를 쓰기위해서 django 및 리액트에서 단순한 작업을 반복하는 것이 비효율 적이라고 생각했다. 그래서 백앤드 API 배포를 지원하는 NextJS를 선택하기로 했다. 지금은, NextJS + Typescript, scss, Prisma, Telefunc을 통해서 블로그를 개발하고 있다.
- NextJS + Typescript
- 우선 JS로 작성된 코드를 TS로 마이그레이션 했다. JS 프로젝트 규모가 커질 수록, 컴포넌트에 들어가는 파라미터들을 관리하기 어려워 졌고, type의 필요성을 느꼈다. 마이그레이션을 진행하면서, 불필요한 상태를 정리하고 컴포넌트간의 props 전달이 명료해 졌다.
- Scss
- scss는 변수, 모듈화, 믹스인 등 다양한 기능을 제공하면서, css와 매우 잘 호환된다. 인터넷 상에서 쉽게 구할 수 있는 css 스타일을 조금만 다듬으면, 내가 원하는 모듈에 그대로 이식할 수 있다. 특별한 상황을 제외하고는 모든 스타일을 scss로 정의하고 있다.
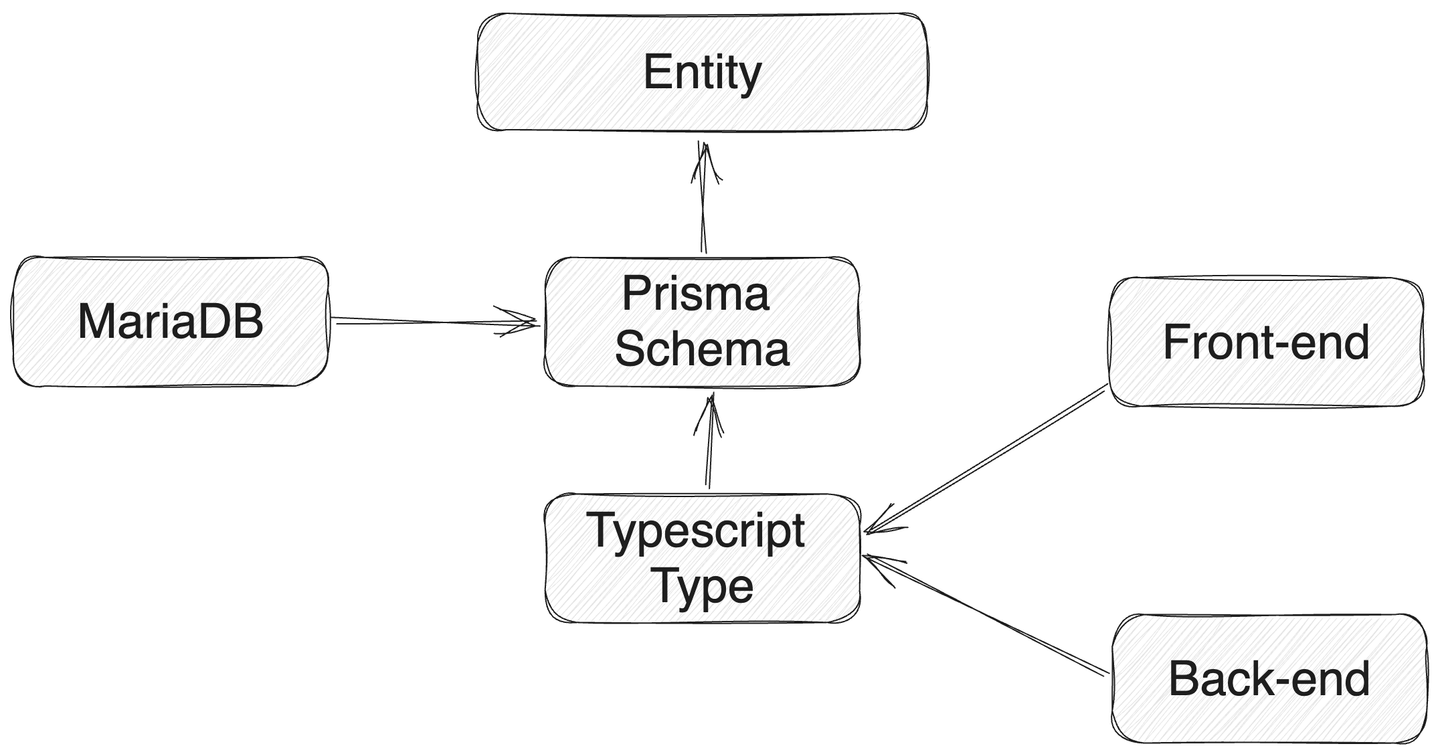
- Prisma(ORM)
- 프론트앤드, 백앤드, DB에서 사용하는 ‘모델’을 하나의 명세서로 관리하고자 하는 생각에서 출발 했다. Prisma는 prisma 문법으로 작성된 스키마를 이용해 typescript 타입을 생성하며 DB를 생성한다. 이 타입을 프론트 및 백에서 모두 import 하여 사용할 수 있다.
- 1+N 문제를 해결하기 위한 Dataloader를 제공한다.
- Telefunc
- 백앤드에서 정의한 함수를 프론트앤드에서 import하여 쓸 수 있다.
- 함수의 파라미터 및 결과 전달이 rest-ful 하게 이뤄지지만, 개발자는 이를 고려할 필요가 없다. 단순히 import 해서 쓰면된다.
- 백앤드에서 Request의 헤더 값을 추출하는 미들웨어가 존재한다. 원한다면 쿠키나 Authorization을 검사하는 것도 가능하다.
Prisma나 NextJS만으로로 개발 속도가 크게 향상되지만, Telefunc을 사용하면 REST API를 전혀 신경쓰지 않아도 된다. 그냥 함수를 만들고 사용하면 된다.
필자는 위 구성으로 백앤드와 프론트앤드를 통합했고, 개발 속도를 크게 개선시켰다.
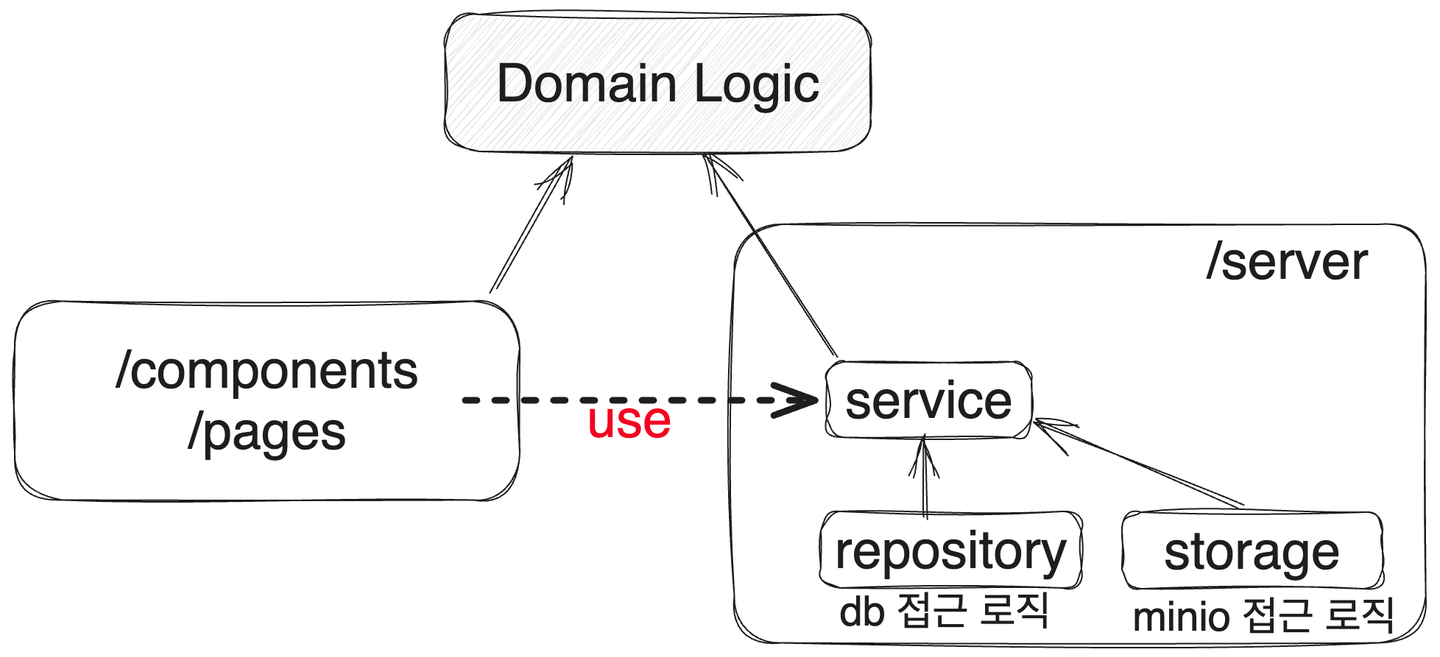
더 나아가 서버에서 실행되는 함수들을 서비스 레이어, 레포지토리 레이어, 스토리지 레이어로 분리했다. 개념적 의존관계 플로우를 정하고, 각 레이어들에게 역할을 부여했다. 결과적으로 하나의 도메인 로직이 정해지면, 변경을 최소화 하면서 빠르게 확장가능한 구조를 구축했다.
개발 환경 - ns: bdg-blog-dev
필자는 다음과 같은 원칙 아래에서 개발 환경을 구축했다.
- 최대한 배포환경과 개발환경을 유사하게 할 것.
- 배포시에는 개발에서만 필요한 환경을 제외하고 배포할 것.
- https 가 적용된 환경에서 테스트가 가능할 것.
우선, 1번과 2번을 구현하기 위해서 Docker의 Multi-Stage Build를 적용했다. 하나의 도커파일에서 빌드용 스테이지와 배포용 스테이지를 분리하고 빌드 스테이지의 이미지와 동일한 환경에서 개발을 진행했다.

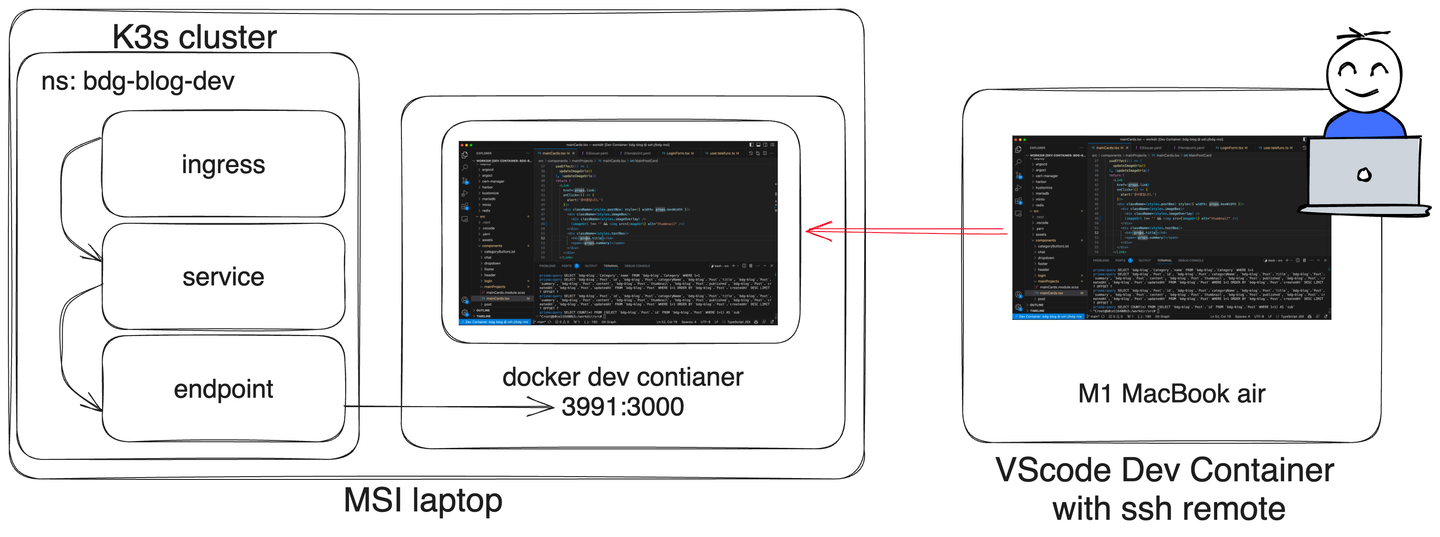
그리고 개발 환경을 localhost:3000으로 접속하는 것이 아닌, https://dev.deagwon.com에서 접속하기 위해 k3s 클러스터위에 개발용 컨테이너를 올렸다. bdg-blog-dev 네임스테이스는 dev.deagwon.com 도메인의 요청을 받으면 이 컨테이너가 올라간 머신의 3991 포트로 요청을 포워딩 하면 필자는 개발중인 라이브 서버를 https 도메인이 붙은 상태로 테스트 할 수 있다. 모바일 기기나 윈도우 기기 등, 다양한 환경에서 화면이 어떻게 보이는 지 실시간으로 확인할 수 있어서 매우 편리했다.
또한 개발 환경이 서버에 세팅되어 있고, 필자의 단순히 리모트 머신으로만 사용한다. 랩탑의 자원을 크게 소비하지 않기 때문에, 발열이나 전원 걱정 없이 어디서든 편하게 개발을 할 수 있었다.
Database - ns: bdg-blog-mariadb
데이터 베이스로는 가장 익숙하게 사용하는 MariaDB를 선택했고, StatefulSet 을 사용해서 배포하고 있다.
Message Broker - ns: bdg-blog-redis
토이 프로젝트로 익명 채팅방을 만들었다.
- bdg blog를 통해서 배포되고 있다.
- bdg blog는 2개의 replicaset을 가지는 deployment이기 때문에 Redis와 같은 메시지 브로커가 필요하다. 이를 위해서 redis를 구축했다.
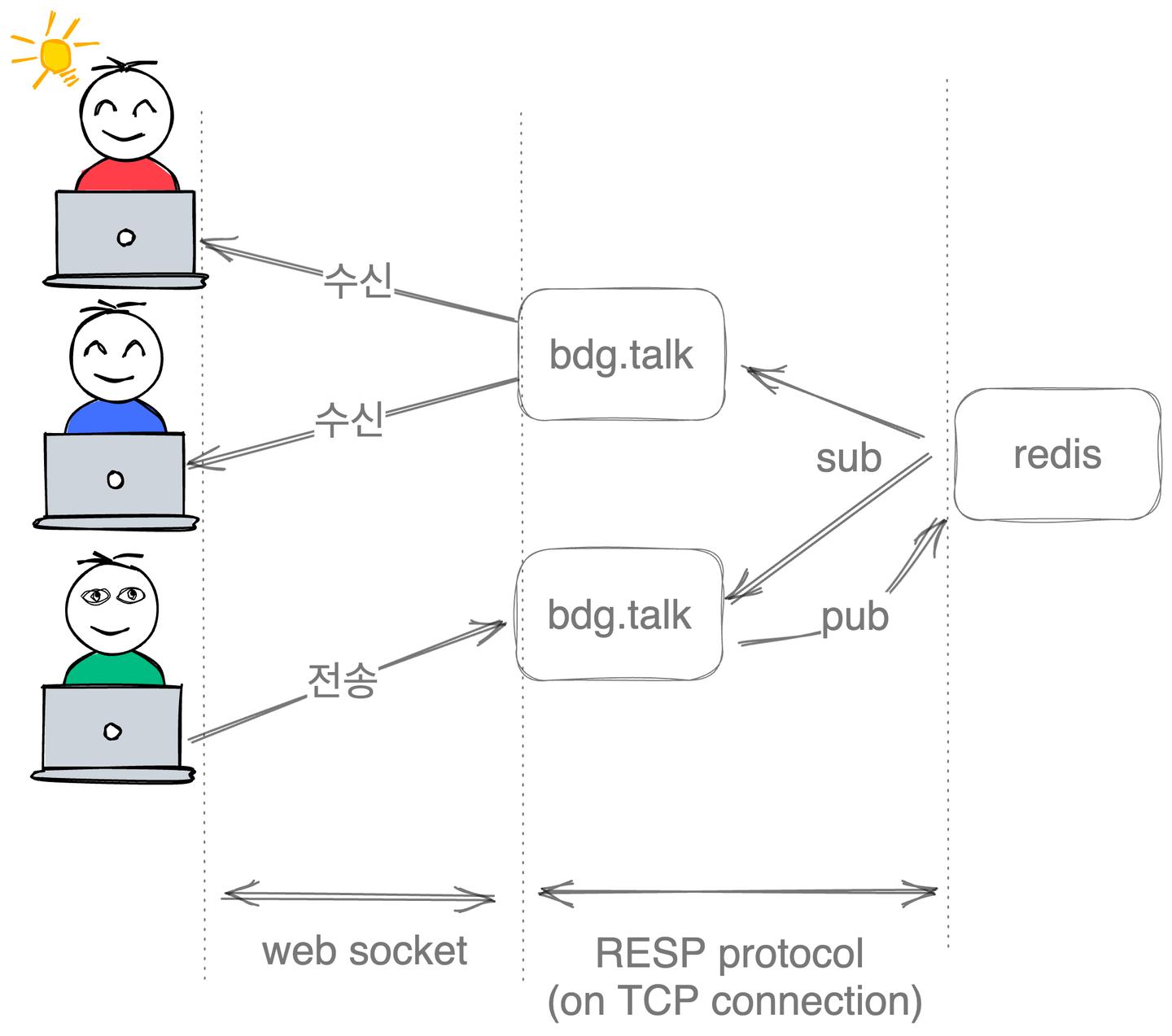
우선 톡앱은 실행되는 순간에 redis와 연결되는 publisher객체와 subscriber객체를 싱글톤으로 생성한다.
사용자가 채팅방에 입장하면 사용자 브라우저와 talk 앱 사이에 web socket connection이 생성된다. 그리고 사용자가 메시지를 보낼 경우, talk 앱은 이 메시지를 publisher 객체를 통해서 브로드 캐스팅하고, Redis는 이 메시지를 다시 subscriber들에게 모두 전달한다. talk 앱에서 subcribe 메시지를 전달 받으면 다시 연결된 사용자에게 이 메시지를 push하는 방식으로 동작한다.
Container Registry - ns: bdg-blog-harbor
초기에 CI/CD 프로젝트를 진행할 때는 AWS의 ECR을 사용했다. 하지만 개인적인 욕심으로 이러한 컨테이너 레지스트리 또한 직접 구축 해보고 싶었기 때문에 Harbor를 올리는 프로젝트를 시작했다. 단순히 harbor를 올리는 것은 Helm Chart를 통해서 손쉽게 가능했다. 약간의 커스텀을 통해서 내가 원하는 컨테이너 레지스트리를 구축했다.
- helm으로 구성된 harbor는 ‘harbor’라는 이름의 ClusterIP service로 expose 된다.
- 외부에서 들어오는 요청은 traefik의 IngressRoute 를 통해서 harbor 서비스로 전달된다.
- 이 ingress 설정 및 tls 인증서를 위한 자원들은 모두 harbor와 동일한 네임스페이스에 위치한다.
하지만 위 조건을 충족하기 위해서는 Helm의 Values.yaml 파일만 수정해서는 해결할 수 없었다. 새롭게 helm chart를 구성하는 것도 방법이지만, 나중에 harbor 의 버전이 업데이트 될 때, 공수가 증가하는 걸 생각하면 좋은 방법은 아니라고 판단했다.
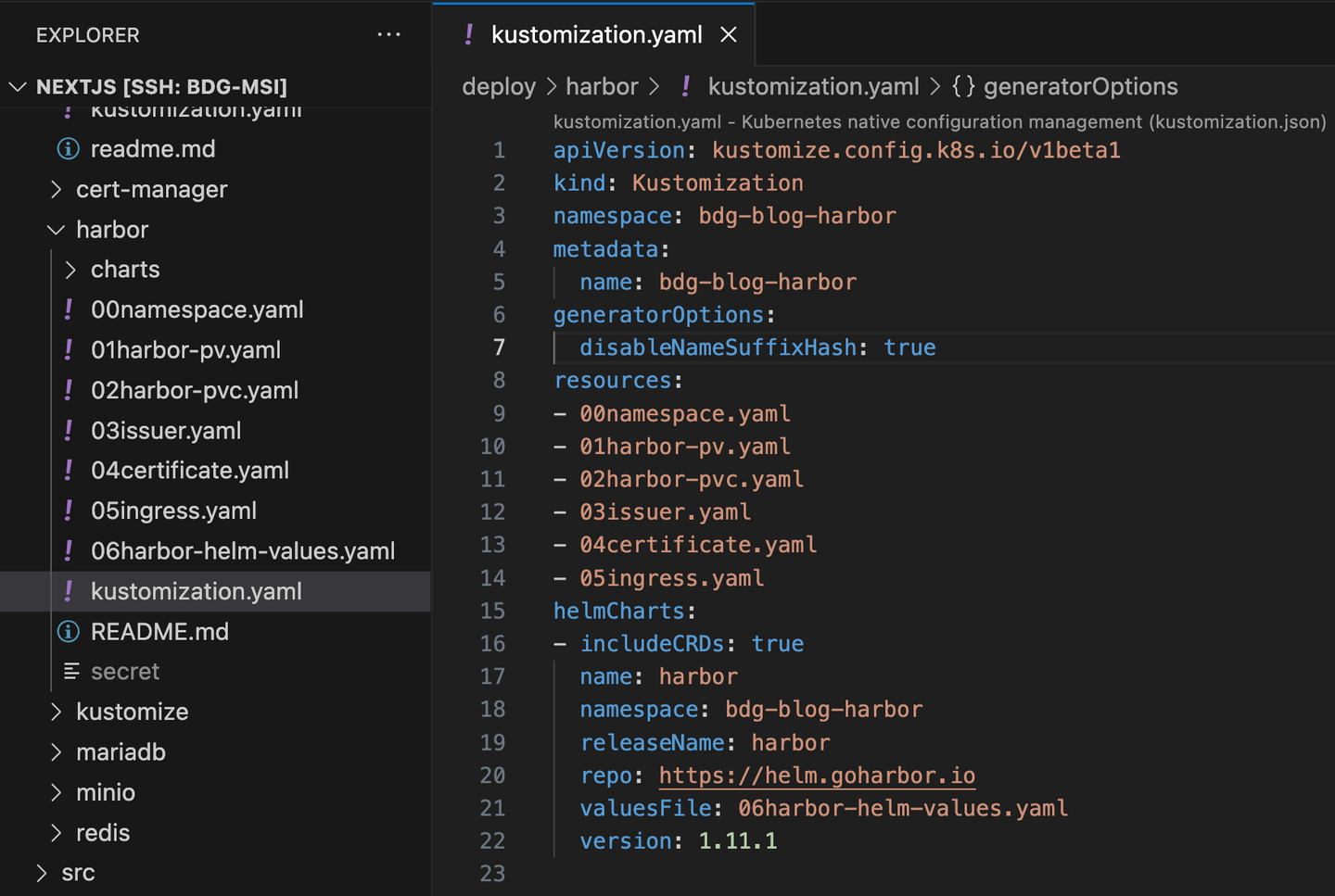
배포되는 harbor helm을 그대로 사용하면서 내가 원하는 자원을 추가하는 방법을 고민한 끝에 kustomize를 사용하기로 결정했다.
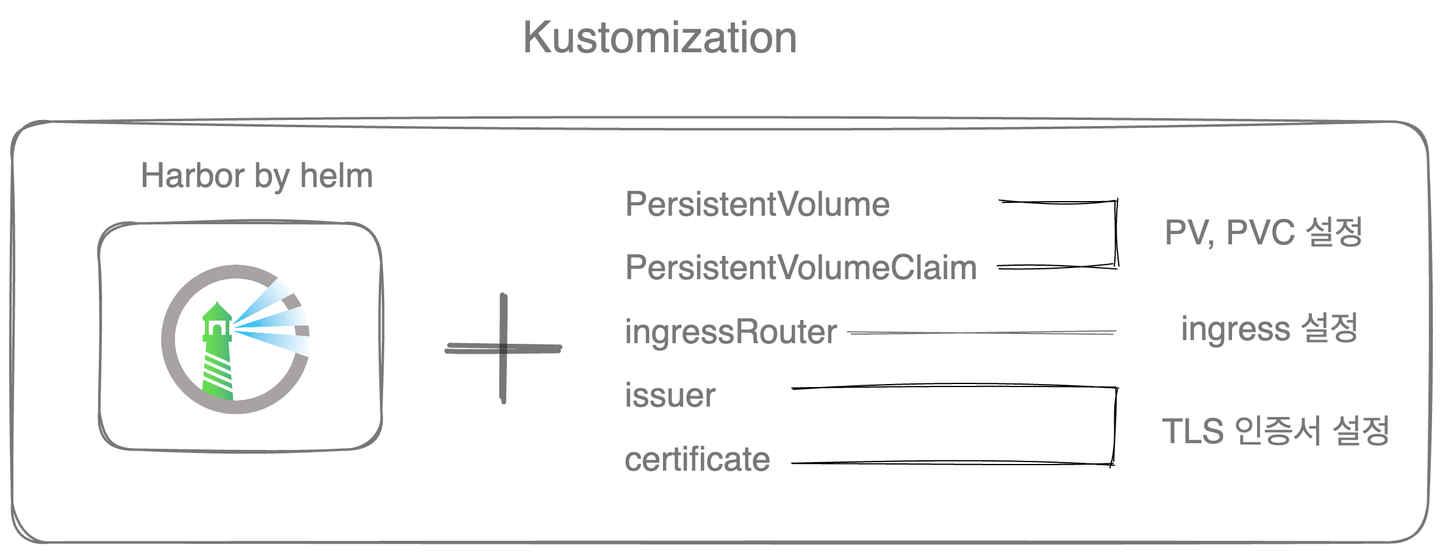
helm chart와 kustomization을 결합하여 harbor를 올리는데 필요한 추가적인 자원들을 정의하고, 관리할 수 있었다. 단, kustomize을 배포하기 위선 --enable-helm 옵션이 추가된다는 점을 주의해야 한다.
Object Storage Server - ns: bdg-blog-minio
minio는 오픈소스로 제공되는 object storage로 AWS의 S3와 호환되며, 다양한 기능(presigned url)들을 제공한다. 필자는 이 블로그의 이미지를 저장하기 위해 minio를 구축했다.
CD tool - ns: bdg-blog-argocd, bdg-blog-argoci
argo events와 argo workflows를 통해서 자동 빌드 배포를 구현하는 것은 어렵지 않았고, 한동안 잘 사용하고 있었다. (argo ci라는 용어는 없지만 argo events와 argo workflows를 합쳐서 이렇게 부르겠다.)
하지만 단순히 공식문서에 나온 방법으로 CI 파이프라인을 구축하면, namespcae별로 구분되는 argo ci를 구성할 수 없다는 사실을 발견했다.
필자는 위 블로그의 글과 같이 하나의 namespace 속에 argoci를 구축한 후, 다른 namespace에 독립적인 argoci를 설치하려고 했었다. 분명히 namespace가 분리되어 있음에도 불구하고, 두 argoci는 동시에 동작하지 못 했다.
사실 이 문제의 원인은 당연했다. argo events와 argo workflows의 설치 스크립트를 살펴보면 CustomResourceDefinition 을 생성하며 ClusterRole 을 정의했다. 그리고 이 둘은 하나의 Cluster Scope에서 동작한다. 만약 B 프로젝트를 위해서 ClusterRole 수정하면, 기존의 A 프로젝트는 정상적으로 동작하지 못하게 되는 것이다.
이 문제를 해결하기 위해서 Cluster Scope에서 동작하는 CustomResourceDefinition 과 ClusterRole 는 따로 설치하고, namespace 범위에서 동작하는 자원들만 프로젝트 단위로 설치할 수 있게 분리했다. 이제 독립적인 ArgoCI가 성공적으로 배포되었다.