배경
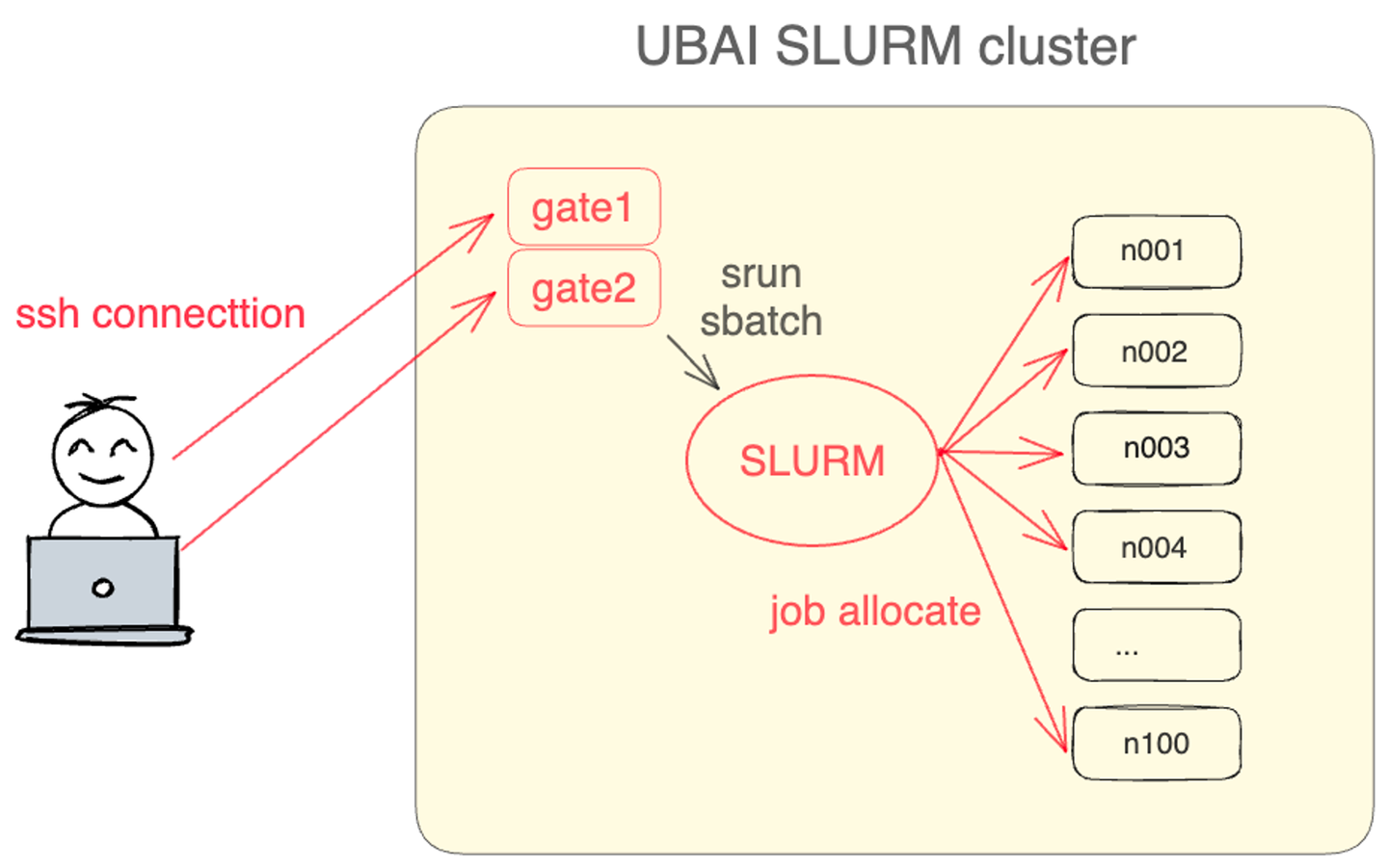
현재 관리하고 있는 HPC 클러스터는 100대의 연산 노드가 Centos7을 사용하고 있습니다. 클러스터의 사용자는 접속이 가능한 gate노드에 ssh로 접속하여 slurm 명령어를 통해서 작업을 제출합니다. slurm은 작업 스케줄링 도구로, 사용자가 제출한 작업을 적절한 연산 노드에 할당하여 작업을 수행합니다. slurm은 cgroup을 사용하여 사용자가 실행한 프로세스의 자원(cpu, memory, gpu)를 제한할 수 있습니다. 또한 사용자는 클러스터에 설치된 Linux Environment Modules 중 필요한 환경을 load 하여 사용합니다. 만약 여기에 필요한 환경이 없다면 권한이 있는 경로에 컴파일된 바이너리 실행파일 혹은 파이썬 가상환경을 직접 설치하여 사용하고 있습니다.
문제점
Linux Environment Modules는 사용자가 여러 버전의 애플리케이션, 라이브러리, 그리고 기타 소프트웨어 패키지를 쉽게 로드하거나 언로드할 수 있도록 도와주는 툴입니다. 국내에 많은 연구기관에서 사용되고 있지만, 다양한 문제점을 가지고 있습니다.
운영체제 의존
Linux Environment Modules는 Host 운영체제에 의존하여 동작합니다. 사용자가 Ubuntu와 같은 다른 운영체제의 패키지를 사용하고자 한다면 사용에 제한이 있습니다.
불완전한 격리
Linux Environment Modules는 완전한 환경 격리를 제공하지 않습니다. 따라서 서로 다른 의존성 라이브러리가 시스템에 설치되어 있을 때 문제가 발생할 수 있습니다.
충돌
불완전한 격리의 연장선으로 충돌 문제가 있습니다. 사용자가 여러 모듈을 동시에 로드할 때, 라이브러리나 의존성 충돌이 발생할 수 있습니다.
관리 포인트 증가
Linux Environment Modules의 환경은 관리자만 생성할 수 있습니다. 사용자의 요청할 때마다 관리자는 새로운 환경을 빌드하고 등록해야 합니다.
해결방법
처음 생각한 방법은 Docker와 같은 컨테이너를 도입하는 것입니다. 혹은 클러스터에 쿠버네티스를 설치한다면 사용자가 원하는 이미지를 사용해 완전히 환경을 격리할 수 있다고 생각했습니다. 하지만 여기에는 몇 가지 문제가 있었습니다. 우선 기존의 Slurm + Linux Environment Modules 사용자를 고려해야 한다는 점입니다. 기존의 사용자는 몇 년간 위 환경으로 연구를 진행해 왔고, 사용하던 환경을 그대로 쓰고 싶어 했습니다.
따라서 기존의 Slurm과 호환되는 커테이너를 사용해야 합니다. 하지만, Docker 및 K8s는 슬럼과 호환되지 않습니다. Slurm은 자체적으로 cgroup을 사용해 job 별 자원을 제한합니다. 하지만 이러한 기능이 K8s나 Docker와 충돌하기 때문에 Slurm과 함께 사용할 수 없었습니다.
여기서 찾은 해결책은 Slurm을 그대로 사용하면서 NVIDIA 사에서 개발한 Enroot라는 반쪽 짜리 컨테이너를 도입하는 것입니다. Enroot는 HCP 클러스터에서 컨테이너와 같은 방식으로 환경을 분리하기 위해 만들어진 프로그램입니다. CNI를 따르지 않으며 자원을 제약하는 기능이 없습니다. 단순히 linux namespace를 통해 환경을 격리하는 기능만 제공합니다. 하지만 docker image를 enroot image로 변환하는 기능을 제공하기 때문에, 사용자가 손쉽게 컨테이너 이미지를 만들 수 있고, slurm에서 enroot 관련 플러그인을 제공하고 있습니다. 또한 NVIDIA 사에서 개발한 만큼, NVIDIA GPU 사용 기능을 기본적으로 제공합니다. enroot를 사용하면 현재 클러스터의 설정을 크게 바꾸지 않고 컨테이너 환경을 구축할 수 있다고 생각해 enroot를 사용하기로 결정했습니다.

- https://github.com/NVIDIA/enroot
설치 방법
커널 커맨드 및 커널 파라미터 수정
enroot 를 설치하기 위해서는 커널 커맨드 및 커널 파라미터를 수정해야 합니다. 아래 문서를 참고하면서 하나씩 진행하겠습니다.
- https://github.com/NVIDIA/enroot/blob/master/doc/requirements.md
./enroot-check_*.run --verify
[root@gate1 container]# ./enroot-check_*.run --verify Kernel version: Linux version 3.10.0-1127.el7.x86_64 (root@tgm-master.hpc) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-39) (GCC) )#1 SMP Thu May 7 14:42:14 KST 2020 Kernel configuration: CONFIG_NAMESPACES : OK CONFIG_USER_NS : OK CONFIG_SECCOMP_FILTER : OK CONFIG_OVERLAY_FS : OK (module) CONFIG_X86_VSYSCALL_EMULATION : KO (required if glibc <= 2.13) CONFIG_VSYSCALL_EMULATE : KO (required if glibc <= 2.13) CONFIG_VSYSCALL_NATIVE : KO (required if glibc <= 2.13) Kernel command line: **namespace.unpriv_enable=1 : KO user_namespace.enable=1 : KO** vsyscall=native : KO (required if glibc <= 2.13) vsyscall=emulate : KO (required if glibc <= 2.13) Kernel parameters: **user.max_user_namespaces : KO** user.max_mnt_namespaces : OK Extra packages: **nvidia-container-cli : KO**
grubby를 사용한 kernel command line 수정
노드의 부팅이미지가 디스크에 있는 경우 grubby 를 이용해서 kernel의 실행 커맨드를 쉽게 수정할 수 있습니다. enroot를 설치한 클러스터에서 게이트 노드, 관리 노드는 아래와 같이 부팅 설정을 변경하고 시스템을 재부팅하여 손쉽게 적용했습니다.
grubby --args="namespace.unpriv_enable=1 user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
echo 'user.max_user_namespaces=15076' >> /etc/sysctl.conf
sysctl --system
pxelinux.cfg 파일을 통한 kernel command line 수정
하지만, 계산 노드는 pxe boot 라는 방식을 이용합니다. pxe(preboot execution environment) boot란 네트워크를 통해 컴퓨터를 부팅하는 기술입니다. pxe server에 저장된 커널 이미지를 pxe client 노드들이 네트워크를 통해서 다운받고, 이를 부팅하는 방식으로 동작합니다. 마스터 노드가 pxe 서버 역할을 하기 때문에, 만약 계산 노드들의 부팅 이미지, 혹은 설정을 변경하기 위해서는 마스터 노드의 pxe 관련 설정을 수정해야 합니다.
/path/to/RBOOT/efi64/pxelinux.cfg
마스터 노드의 위 경로에 노드별로 부팅 설정 파일이 저장되어 있었습니다.
[root@master pxelinux.cfg]# ls
C0A86401 C0A86412 C0A86423 C0A86434 C0A86445 C0A86456 C0A86467 C0A86478 C0A86489
C0A86402 C0A86413 C0A86424 C0A86435 C0A86446 C0A86457 C0A86468 C0A86479 C0A8648A
C0A86403 C0A86414 C0A86425 C0A86436 C0A86447 C0A86458 C0A86469 C0A8647A C0A8648B
C0A86404 C0A86415 C0A86426 C0A86437 C0A86448 C0A86459 C0A8646A C0A8647B C0A8648C
C0A86405 C0A86416 C0A86427 C0A86438 C0A86449 C0A8645A C0A8646B C0A8647C C0A8648D
...
[root@master pxelinux.cfg]# cat C0A86401
DEFAULT TGMkernel
LABEL TGMkernel
KERNEL http://192.168.100.1/KERNEL/kernel.img
APPEND initrd=http://192.168.100.1/KERNEL/n033_ramfs.tgm quiet
rd_NO_DM ip=eth0:dhcp ETHERNET=eth0 NISDOMAIN=TGM rw selinux=0
net.ifnames=0 biosdevname=0 intel_idle.max_cstate=0 processor.max_cstate=1
ipv6.disable=1 cgroup_enable=memory swapaccount=1 intel_pstate=disable rdblacklist=nouveau
nouveau.modeset=0 vga=normal nofb i915.modeset=0 spectre_v2=off nospectre_v1 nospectre_v2
nopti rhgb nomodeset video=vesafb:off panic=60
nfs.nfs4_unique_id=3dc56ea0-d930-464c-80e6-1ec1f9f4b1c1
해당 파일마다 namespace.unpriv_enable=1 user_namespace.enable=1 라인을 추가하여 pxe 설정파일을 수정했습니다.
#!/bin/bash
cd /path/to/RBOOT/efi64/
cp -pr pxelinux.cfg pxelinux.cfg.bk
list=`ls pxelinux.cfg`
for text in $list
do
echo $text
sed -e '$s/$/namespace.unpriv_enable=1 user_namespace.enable=1/' -s $text > $text
done
그 결과, 모든 계산 노드의 커널 커맨드가 수정되었습니다.
[root@tgm-master pxelinux.cfg]# cat C0A86401
DEFAULT TGMkernel
LABEL TGMkernel
KERNEL http://pxe-server-ip/KERNEL/kernel.img
APPEND initrd=http://pxe-server-ip/KERNEL/n0XX_ramfs.tgm quiet
rd_NO_DM ip=eth0:dhcp ETHERNET=eth0 NISDOMAIN=TGM rw selinux=0
net.ifnames=0 biosdevname=0 intel_idle.max_cstate=0 processor.max_cstate=1
ipv6.disable=1 cgroup_enable=memory swapaccount=1 intel_pstate=disable rdblacklist=nouveau
nouveau.modeset=0 vga=normal nofb i915.modeset=0 spectre_v2=off nospectre_v1 nospectre_v2
nopti rhgb nomodeset video=vesafb:off panic=60
nfs.nfs4_unique_id=3dc56ea0-d930-464c-80e6-1ec1f9f4b1c1
**namespace.unpriv_enable=1 user_namespace.enable=1**
Kernel parameters 수정
커널 파라미터는 /etc/sysctl.conf 를 수정하여 변경할 수 있는데, 모든 계산 노드 etc 폴더가 마스터 노드에 NFS로 마운트되어 있습니다. 따라서 마스터 노드에서 일괄적으로 수정이 가능합니다.
[root@tgm-master NODES]#
list=`ls ./*/etc/sysctl.conf`
for loc in $list
do
echo 'user.max_user_namespaces=15076' >> $loc
done
이후 모든 계산노드를 재부팅하여 설정을 갱신했습니다.
nvidia-container-cli 설치
enroot로 gpu를 사용하기 위해서는 nvidia-container-cli이 필요합니다. 아래 가이드를 참고해 설치했습니다.
- https://github.com/NVIDIA/libnvidia-container
- https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#installation-guide
# yum 레파지토리 추가
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.repo | sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
yum-config-manager --enable libnvidia-container-experimental
yum clean expire-cache
# nvidia-container-cli 설치
yum install -y libnvidia-container1
yum install -y libnvidia-container-tools
-
nvidia_uvm이 없는 문제 해결
일부 노드에서 NVIDIA driver가 완전하기 실행되지 않고, UVM 커널 모듈이 빠진 경우 아래와 같은 오류가 발생했습니다.
nvidia-container-cli -k info커맨드를 통해서 드라이버를 다시 로드하여 해결했습니다. 만약 같은 문제가 반복된다면, 시스템 데몬으로 등록하여 리로드를 강제할 수 있다고 합니다.(https://github.com/NVIDIA/enroot/issues/105)
# nvidia_uvm 없음.
#[WARN] Kernel module nvidia_uvm is not loaded. Make sure the NVIDIA device driver is installed and loaded.
$# nvidia-container-cli -k info
-
libnvidia-ml.so 못 찾는 문제 해결
찾아보니 debian 계열의 운영체제에서 유사한 에러가 발생했고, 원인은 /sbin/ldconfig 와 관련된 경로가 달라서 생기는 오류라고 합니다.
이 클러스터는 centos7이기 때문에 완전히 같은 원인은 아니겠지만, 비슷한 이유로 ldconfig를 실행하지 못해 공유 라이브러리 링커가 잘 연결되지 않았다면, *.so 관련 에러가 발생할 수 있을 것이라 생각했습니다.
ldconfig를 수동으로 실행했더니 문제가 해결됐습니다.
다시 Enroot pre-requirement 검사
필요한 설정들을 마치고 다시 enroot-pre-requirement를 실행하여 시스템 설정이 잘 적용 됐는지 확인했습니다.
./enroot-check_*.run --verify
[root@gate1 container]# ./enroot-check_*.run --verify
Kernel version:
Linux version 3.10.0-1127.el7.x86_64 (root@tgm-master.hpc) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-39) (GCC) )#1 SMP Thu May 7 14:42:14 KST 2020
Kernel configuration:
CONFIG_NAMESPACES : OK
CONFIG_USER_NS : OK
CONFIG_SECCOMP_FILTER : OK
CONFIG_OVERLAY_FS : OK (module)
CONFIG_X86_VSYSCALL_EMULATION : KO (required if glibc <= 2.13)
CONFIG_VSYSCALL_EMULATE : KO (required if glibc <= 2.13)
CONFIG_VSYSCALL_NATIVE : KO (required if glibc <= 2.13)
Kernel command line:
**namespace.unpriv_enable=1 : OK
user_namespace.enable=1 : OK**
vsyscall=native : KO (required if glibc <= 2.13)
vsyscall=emulate : KO (required if glibc <= 2.13)
Kernel parameters:
user.max_user_namespaces : OK
user.max_mnt_namespaces : OK
Extra packages:
**nvidia-container-cli : OK**
Enroot 설치 - https://github.com/NVIDIA/enroot
nvidia-container-cli 마찬가지로 master 노드에 yum으로 간단하게 설치할 수 있습니다.
3. enroot 설치(https://github.com/NVIDIA/enroot)
arch=$(uname -m)
yum install -y epel-release
yum install -y https://github.com/NVIDIA/enroot/releases/download/v3.4.0/enroot-hardened-3.4.0-2.el7.${arch}.rpm
yum install -y https://github.com/NVIDIA/enroot/releases/download/v3.4.0/enroot-hardened+caps-3.4.0-2.el7.${arch}.rpm
enroot 를 설치하면 노드마다 /etc/enroot/enroot.conf 라는 경로에 설정파일이 생성됩니다. 이 설정 파일을 수정하여 enroot를 커스텀할 수 있다고 합니다. 현재 클러스터 상황에 맞게 일부 설정을 수정하였습니다.
-
runtime, data, temp 경로를 /disk 로 수정
현재 클러스터는 사용자 계정이 NFS 볼륨에 마운트 되어 있습니다. enroot의 runtime, data, temp 경로를 /home/user 아래에 생성하면, 손쉽게 컨테이너를 동기화할 수 있지만, NFS 볼륨은 사용량이 많아 IO 가 매우 느리다는 단점이 있습니다. 특히 패키지 설치와 같은 쓰기 작업 속도가 매우 느리기 때문에 disk 볼륨을 런타임 및 데이터 경로로 사용하기로 결정했다. 둘의 차이를 비교해본 결과 nfs 볼륨을 사용할 때보다 훨씬 빠른 작업 속도를 보였습니다.
-
이미지 압축 옵션 변경
enroot는 다양한 압축 알고리즘을 지원합니다. 이 클러스터는 스토리지 공간에 여유가 있기 때문에, 컨테이너 이미지가 커도 압축 속도가 빠른 gzip 알고리즘을 사용하도록 변경했습니다. 또한 특정 레이어 사이즈가 스토리지 블록 사이즈 보다 클 경우, 이미지를 export하지 못하는 문제가 있었는데, 이를 해결하기 위해 fragments를 허용하는 옵션을 추가했습니다.
# /etc/enroot/enroot.conf
ENROOT_RUNTIME_PATH=/disk/enroot/$(id -u)/runtime
ENROOT_DATA_PATH=/disk/enroot/$(id -u)/data
ENROOT_CACHE_PATH=/disk/enroot/$(id -u)/cache
ENROOT_TEMP_PATH=/disk/enroot/$(id -u)
ENROOT_SQUASH_OPTIONS='-comp gzip -noD -always-use-fragments'
ENROOT_MAX_PROCESSORS 10
결론
이제 사용자가 자유롭게 도커 컨테이너로부터 작업 환경을 가져올 수 있게 됐습니다. 더욱이 NFS에 의존하지 않으면서 환경을 구축하고, 실행할 수 있기 때문에 작업 속도가 크게 증가했습니다.
저로서는 이번 enroot를 설치하면서 많은 공부가 되었습니다. HPC 클러스터에 의존하는 설정 덕분에 다양한 문제들을 마주했고, 이 문제들을 해결해 가면서 운영체제, HPC 구성에 대한 이해를 높일 수 있는 시간이었습니다.
Reference
- https://slurm.schedmd.com/SLUG19/NVIDIA_Containers.pdf
- https://slurm.schedmd.com/qos.html
- https://github.com/NVIDIA/enroot
- “Performance Analysis of Container-based Virtualization for High Performance Computing Environments” by Kozhirbayev, Zhandos, and Richard O. Sinnott.